

Kafka 상세 가이드
1. Kafka란 무엇인가?
Kafka는 LinkedIn에서 개발하고 현재는 Apache 재단에서 관리하는 분산 스트리밍 플랫폼입니다. 대용량의 실시간 데이터 스트림을 안정적으로 처리할 수 있도록 설계되었으며, 다음과 같은 특징을 가지고 있습니다:
- 고성능: 초당 수백만 개의 메시지를 처리할 수 있는 높은 처리량
- 확장성: 클러스터 구성을 통해 수평적 확장 가능
- 내구성: 데이터를 디스크에 저장하여 데이터 손실 방지
- 분산 처리: 여러 서버에 데이터를 분산하여 저장 및 처리
2. Kafka의 주요 개념
2.1. 메시지(Message)
Kafka에서 데이터의 기본 단위입니다. 키(Key)와 값(Value)으로 구성되며, 타임스탬프와 메타데이터도 포함할 수 있습니다.
2.2. 토픽(Topic)
메시지가 저장되는 논리적인 채널입니다. 토픽은 이름을 가지며, 여러 생산자가 메시지를 발행하고 여러 소비자가 메시지를 구독할 수 있습니다. 예를 들어, 질문-답변 서비스에서는 question-events, answer-events와 같은 토픽을 만들 수 있습니다.
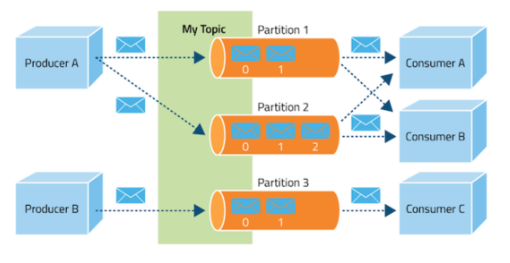
2.3. 파티션(Partition)
토픽은 여러 파티션으로 나뉘어 분산 저장됩니다. 각 파티션은 순서가 보장된 메시지 시퀀스이며, 파티션 내에서는 메시지가 추가된 순서대로 고유한 오프셋(offset)이 할당됩니다. 파티션을 통해 병렬 처리가 가능해집니다.
2.4. 브로커(Broker)
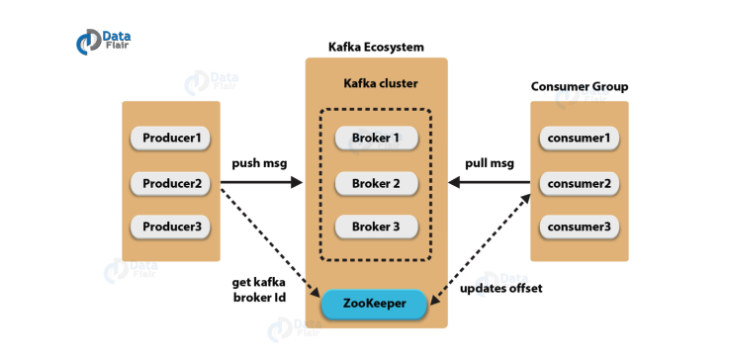
Kafka 서버를 의미합니다. 하나의 브로커는 여러 토픽의 여러 파티션을 호스팅할 수 있습니다. 여러 브로커가 모여 Kafka 클러스터를 구성합니다.
2.5. 프로듀서(Producer)
메시지를 생성하여 토픽에 발행하는 클라이언트 애플리케이션입니다. 프로듀서는 메시지를 어떤 토픽의 어떤 파티션에 발행할지 결정할 수 있습니다.
2.6. 컨슈머(Consumer)
토픽으로부터 메시지를 구독하여 처리하는 클라이언트 애플리케이션입니다. 컨슈머는 토픽의 특정 파티션에서 메시지를 순차적으로 읽습니다.
2.7. 컨슈머 그룹(Consumer Group)
여러 컨슈머를 그룹화하여 토픽의 파티션을 분산해서 처리할 수 있게 합니다. 하나의 파티션은 같은 컨슈머 그룹 내의 하나의 컨슈머만 처리할 수 있습니다.

2.8. Zookeeper
Kafka 클러스터의 메타데이터를 관리하고 브로커, 토픽, 파티션 등의 상태를 조정하는 역할을 합니다. 최신 버전의 Kafka에서는 Zookeeper 의존성을 제거하는 방향으로 발전하고 있습니다(KRaft 모드).
3. Kafka의 동작 원리

3.1. 메시지 발행 과정
- 프로듀서가 메시지를 생성합니다.
- 메시지는 특정 토픽의 특정 파티션으로 전송됩니다.
- 파티션 결정은 다음과 같이 이루어집니다:
- 메시지에 파티션이 명시적으로 지정된 경우, 해당 파티션으로 전송
- 메시지에 키가 있고 파티션이 지정되지 않은 경우, 키의 해시값을 기반으로 파티션 결정
- 메시지에 키가 없고 파티션도 지정되지 않은 경우, 라운드 로빈 방식으로 파티션 결정
- 브로커는 메시지를 받아 해당 파티션에 추가하고 오프셋을 할당합니다.
- 브로커는 메시지 저장 성공 여부를 프로듀서에게 응답합니다.
3.2. 메시지 소비 과정
- 컨슈머는 특정 토픽을 구독합니다.
- 컨슈머 그룹 내에서 파티션이 컨슈머에게 할당됩니다.
- 컨슈머는 할당된 파티션에서 메시지를 순차적으로 읽습니다.
- 컨슈머는 처리한 메시지의 오프셋을 커밋하여 어디까지 처리했는지 기록합니다.
- 컨슈머가 실패하면 다른 컨슈머가 해당 파티션을 이어받아 마지막으로 커밋된 오프셋부터 처리를 계속합니다.
3.3. 데이터 보존 정책
Kafka는 메시지를 영구적으로 저장하지 않고, 설정된 보존 정책에 따라 데이터를 관리합니다:
- 시간 기반 보존: 설정된 시간(예: 7일)이 지난 메시지는 자동으로 삭제
- 크기 기반 보존: 파티션 크기가 설정된 한도에 도달하면 오래된 메시지부터 삭제
- 압축(Compaction): 같은 키를 가진 메시지 중 최신 메시지만 유지하고 나머지는 삭제
4. Kafka의 주요 기능
4.1. 고가용성과 내구성
- 복제(Replication): 각 파티션은 여러 브로커에 복제되어 저장됩니다. 복제 팩터(Replication Factor)를 통해 복제본 수를 설정할 수 있습니다.
- 리더와 팔로워(Leader and Follower): 각 파티션에는 하나의 리더와 여러 팔로워가 있습니다. 모든 읽기와 쓰기 작업은 리더를 통해 이루어지며, 팔로워는 리더의 데이터를 복제합니다.
- 자동 장애 복구: 브로커가 실패하면 해당 브로커가 리더였던 파티션은 다른 브로커의 복제본이 리더로 교체 됩니다.
4.2. 확장성
- 수평적 확장: 브로커를 추가하여 클러스터의 용량과 처리량을 늘릴 수 있습니다.
- 파티션 확장: 토픽의 파티션 수를 늘려 병렬 처리 능력을 향상시킬 수 있습니다.
4.3. 스트림 처리
- Kafka Streams: Kafka에 내장된 스트림 처리 라이브러리로, 실시간 데이터 처리 애플리케이션을 개발할 수 있습니다.
- KSQL: SQL과 유사한 문법으로 스트림 처리를 할 수 있는 도구입니다.
5. Kafka 설치 및 기본 사용법 (Q&A 서비스 기반)
참고 사이트
Kafka 와 Spring Boot 애플리케이션 연동
Kafka 개념과 Spring Boot + Kafka 간단한 연동
SpringBoot3.x.x에서 Kafka 연동하기
5.1. Docker를 이용한 Kafka 설치 (로컬 환경)
5.1. Docker를 이용한 Kafka 설치 (로컬 환경)
docker-compose.yml 파일 생성:
version: '3' services: zookeeper: image: confluentinc/cp-zookeeper:latest container_name: zookeeper environment: ZOOKEEPER_CLIENT_PORT: 2181 ZOOKEEPER_TICK_TIME: 2000 ports: - "2181:2181" networks: - kafka-network kafka: image: confluentinc/cp-kafka:latest container_name: kafka depends_on: - zookeeper ports: - "9092:9092" environment: KAFKA_BROKER_ID: 1 KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181 KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://localhost:9092 KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1 KAFKA_AUTO_CREATE_TOPICS_ENABLE: "true" networks: - kafka-network kafka-ui: image: provectuslabs/kafka-ui:latest container_name: kafka-ui depends_on: - kafka ports: - "8080:8080" environment: KAFKA_CLUSTERS_0_NAME: local KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS: kafka:9092 KAFKA_CLUSTERS_0_ZOOKEEPER: zookeeper:2181 networks: - kafka-network networks: kafka-network: driver: bridgeDocker Compose 실행:
docker-compose up -dKafka UI 접속:
브라우저에서http://localhost:8080으로 접속하여 Kafka UI를 통해 토픽, 브로커 등을 관리할 수 있습니다.
5.2. 토픽 생성
Docker 컨테이너에 접속하여 토픽을 생성합니다:
docker exec -it kafka kafka-topics --create --topic question-events --bootstrap-server localhost:9092 --partitions 3 --replication-factor 1또는 Kafka UI를 통해 토픽을 생성할 수 있습니다:
http://localhost:8080에 접속- "Topics" 메뉴 선택
- "Add a Topic" 버튼 클릭
- 토픽 이름, 파티션 수, 복제 팩터 등 설정 후 생성
5.3. 토픽 목록 확인
docker exec -it kafka kafka-topics --list --bootstrap-server localhost:90925.4. 토픽 상세 정보 확인
docker exec -it kafka kafka-topics --describe --topic question-events --bootstrap-server localhost:90925.5. 콘솔 프로듀서 실행
docker exec -it kafka kafka-console-producer --topic question-events --bootstrap-server localhost:9092메시지 입력 후 Enter 키를 누르면 메시지가 토픽으로 전송됩니다. 입력을 종료하려면 Ctrl+D를 누릅니다.
5.6. 콘솔 컨슈머 실행
docker exec -it kafka kafka-console-consumer --topic question-events --from-beginning --bootstrap-server localhost:90926. Spring Boot에서 Kafka 사용하기
6.1. 의존성 추가
dependencies {
implementation 'org.springframework.kafka:spring-kafka'
}6.2. Kafka 설정
@Configuration
public class KafkaConfig {
@Bean
public ProducerFactory<String, String> producerFactory() {
Map<String, Object> configProps = new HashMap<>();
configProps.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
configProps.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
configProps.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
return new DefaultKafkaProducerFactory<>(configProps);
}
@Bean
public KafkaTemplate<String, String> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
@Bean
public ConsumerFactory<String, String> consumerFactory() {
Map<String, Object> configProps = new HashMap<>();
configProps.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
configProps.put(ConsumerConfig.GROUP_ID_CONFIG, "question-service");
configProps.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
configProps.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
return new DefaultKafkaConsumerFactory<>(configProps);
}
@Bean
public ConcurrentKafkaListenerContainerFactory<String, String> kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, String> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
return factory;
}
}6.3. 메시지 발행
@Service
public class QuestionEventPublisher {
private final KafkaTemplate<String, String> kafkaTemplate;
private final ObjectMapper objectMapper;
public QuestionEventPublisher(KafkaTemplate<String, String> kafkaTemplate, ObjectMapper objectMapper) {
this.kafkaTemplate = kafkaTemplate;
this.objectMapper = objectMapper;
}
public void publishQuestionCreatedEvent(QuestionDto questionDto) throws JsonProcessingException {
String payload = objectMapper.writeValueAsString(questionDto);
kafkaTemplate.send("question-events", payload);
}
}6.4. 메시지 소비
@Service
public class QuestionEventConsumer {
private final ObjectMapper objectMapper;
public QuestionEventConsumer(ObjectMapper objectMapper) {
this.objectMapper = objectMapper;
}
@KafkaListener(topics = "question-events", groupId = "notification-service")
public void consumeQuestionEvent(String message) throws JsonProcessingException {
QuestionDto questionDto = objectMapper.readValue(message, QuestionDto.class);
// 이벤트 처리 로직
System.out.println("Received question event: " + questionDto);
}
}6.5. Spring Cloud Stream 사용
Spring Cloud Stream은 메시지 브로커와의 통합을 추상화하여 더 간편하게 사용할 수 있게 해줍니다.
@Configuration
public class StreamConfig {
@Bean
public Function<QuestionCreatedEvent, QuestionCreatedEvent> processQuestionCreated() {
return event -> {
// 이벤트 처리 로직
System.out.println("Processing question created event: " + event);
return event;
};
}
}spring:
cloud:
function:
definition: processQuestionCreated
stream:
kafka:
binder:
brokers: localhost:9092
bindings:
processQuestionCreated-in-0:
destination: question-events
contentType: application/json
processQuestionCreated-out-0:
destination: processed-question-events
contentType: application/json6.5. 최종 아키텍처
이벤트 흐름:
- 사용자가 질문/답변 서비스에 질문을 생성/수정/삭제합니다.
- QuestionService가 DB 작업을 수행하고 QuestionEventPublisher를 통해 이벤트를 발행합니다.
- Kafka가 이벤트를 수신하고 토픽에 저장합니다.
- 알림 서비스의 QuestionEventConsumer가 이벤트를 구독하여 처리합니다.
- NotificationService가 필요한 알림을 생성하고 사용자에게 전달합니다.
도커 구성 설명:
- Zookeeper: Kafka 클러스터의 메타데이터 관리 및 브로커 조정
- Kafka: 이벤트 스트리밍 플랫폼으로 토픽을 통해 서비스 간 메시지 전달
- Kafka UI: 토픽, 브로커 등을 모니터링하고 관리하는 웹 인터페이스
- 질문/답변 서비스: 질문과 답변을 관리하고 이벤트를 발행하는 서비스
- 알림 서비스: 이벤트를 구독하여 사용자에게 알림을 전송하는 서비스
7. Kafka 운영 및 모니터링
7.1. 클러스터 구성 권장사항
- 브로커 수: 최소 3대 이상의 브로커를 구성하여 고가용성 확보
- 복제 팩터: 최소 2 이상으로 설정하여 데이터 내구성 확보
- 파티션 수: 토픽의 처리량과 컨슈머 수를 고려하여 적절히 설정
7.2. 모니터링 도구
- Kafka Manager: LinkedIn에서 개발한 Kafka 클러스터 관리 도구
- Confluent Control Center: Confluent에서 제공하는 상용 모니터링 도구
- Prometheus & Grafana: 오픈소스 모니터링 스택을 활용한 Kafka 모니터링
- JMX 모니터링: Kafka는 JMX를 통해 다양한 메트릭을 제공
7.3. 성능 튜닝
- 배치 처리: 프로듀서와 컨슈머의 배치 설정을 조정하여 처리량 향상
- 압축: 메시지 압축을 활성화하여 네트워크 대역폭 절약
- 메모리 설정: 브로커의 힙 메모리와 페이지 캐시 설정 최적화
- 디스크 I/O: 고성능 디스크 사용 및 RAID 구성 고려
8. Kafka 사용 사례
8.1. 로그 수집
시스템 로그, 애플리케이션 로그 등을 Kafka를 통해 중앙 집중화하여 처리할 수 있습니다. ELK(Elasticsearch, Logstash, Kibana) 스택과 함께 사용하면 효과적인 로그 분석 시스템을 구축할 수 있습니다.
8.2. 이벤트 소싱(Event Sourcing)
시스템의 상태 변화를 이벤트로 저장하고 이를 기반으로 현재 상태를 재구성하는 패턴입니다. Kafka는 이벤트 저장소로 활용될 수 있습니다.
8.3. 실시간 분석
스트리밍 데이터를 실시간으로 처리하여 인사이트를 도출하는 데 활용됩니다. Kafka Streams나 Apache Flink와 같은 스트림 처리 엔진과 함께 사용됩니다.
8.4. 마이크로서비스 통합
마이크로서비스 간의 비동기 통신을 위한 메시지 버스로 활용됩니다. 서비스 간 느슨한 결합을 구현하고 확장성을 높일 수 있습니다.
8.5. CDC(Change Data Capture) 구현
데이터베이스의 변경 사항을 실시간으로 감지하고 Kafka로 전송하는 CDC 패턴을 구현할 수 있습니다. Debezium을 사용하면 데이터베이스의 변경 사항을 자동으로 감지하여 Kafka 토픽으로 전송할 수 있습니다. 이를 통해 데이터 동기화, 이벤트 소싱, 실시간 분석 등 다양한 시나리오를 구현할 수 있습니다.
8.5.1. Debezium 적용 사례
- 데이터 동기화
- 마이크로서비스 간의 데이터 동기화
- 데이터 웨어하우스 구축
- 캐시 갱신
- 이벤트 기반 아키텍처
- 데이터베이스 변경 사항을 이벤트로 변환
- 마이크로서비스 간 이벤트 기반 통신
- CQRS 패턴 구현
- 실시간 모니터링
- 데이터베이스 변경 사항 실시간 추적
- 데이터 품질 모니터링
- 감사 로그 생성
9. Kafka와 다른 메시지 브로커 비교
9.1. Kafka vs ActiveMQ
Kafka: 대용량 데이터 처리, 높은 확장성, 이벤트 스트리밍에 최적화
ActiveMQ: JMS 표준 준수, 다양한 메시징 패턴 지원, 기업 환경에서의 안정성
9.2. Kafka vs Redis Pub/Sub
- Kafka: 메시지 지속성, 높은 처리량, 파티셔닝을 통한 병렬 처리
- Redis Pub/Sub: 간단한 구현, 낮은 지연 시간, 메모리 기반 처리
10. 결론
이벤트 기반 아키텍처(EDA)와 Kafka를 활용하면 질문/답변 서비스와 알림 서비스 간의 느슨한 결합을 구현할 수 있습니다. 이를 통해 각 서비스는 독립적으로 개발, 배포, 확장될 수 있으며, 시스템 전체의 확장성과 유연성이 향상됩니다.
Kafka의 내구성과 확장성은 메시지가 손실되지 않고 안정적으로 전달되도록 보장하며, 시스템의 부하가 증가하더라도 효과적으로 대응할 수 있습니다.
'개발' 카테고리의 다른 글
| Kafka와 RabbitMQ 비교 분석 (0) | 2025.03.21 |
|---|---|
| 테스트 코드의 중요성? (SpringBoot 기반 Mocking 학습) (0) | 2025.03.21 |
| Spring Boot - Builder 패턴 (0) | 2025.03.12 |
| Spring Boot에 Mysql Docker 연결 (0) | 2024.05.14 |
| Selenium (0) | 2024.05.13 |
IT/네트워크/보안



